RAG dans Datacloud : Transformez vos documents internes en alliés puissants pour l’IA
RAG dans Datacloud : Transformez vos documents internes en alliés puissants pour l’IA


22Et si vos documents internes devenaient vos meilleurs alliés pour booster l’intelligence de vos agents ? C’est exactement ce que permet le RAG (Retrieval Augmented Generation) dans DataCloud, notamment avec Agentforce.
L’IA générative séduit et impressionne, mais dans un contexte métier, une bonne réponse ne doit pas seulement être brillante — elle doit être pertinente, précise et alignée avec votre contexte. C’est là qu’intervient le RAG : une approche qui permet à l’IA de s’appuyer directement sur vos propres documents pour formuler ses réponses.
Aujourd’hui, nous vous expliquons concrètement comment ça marche dans DataCloud, en deux temps :
- Ce qui se passe en amont, dans l’ombre, avant toute interaction
- Ce qui se joue en temps réel, quand l’utilisateur pose sa question
Cet article se concentre sur l’alimentation et l’utilisation des Data Library avec le RAG dans DataCloud et Agentforce.
Ce qui se passe avant l’utilisation : Les coulisses du RAG
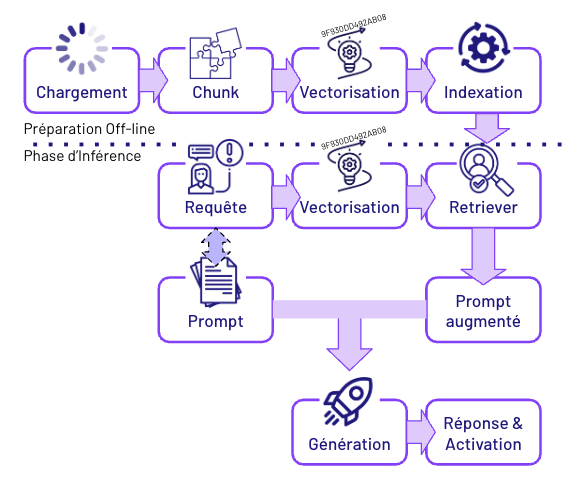
On parle beaucoup des prouesses de l’IA, mais sans préparation, pas de magie. Toute la force du RAG repose sur un travail méthodique réalisé en amont. Voici les étapes clés :
1. Intégration des documents
Tout commence par l’importation de vos documents métier. Dans DataCloud, vous pouvez intégrer ces fichiers via différents canaux : Agentforce, Mulesoft, systèmes externes, et Data Library.
Formats supportés : PDF, RTF, HTML, entre autres. Autrement dit, votre documentation interne, vos procédures, vos guides produits ou vos FAQ ont toute leur place dans la boucle IA.
Exemple concret : vous chargez un guide technique en PDF et des procédures internes en HTML. L’objectif : que l’IA puisse s’en servir plus tard pour répondre précisément.
2. Découpage en chunks
Les documents sont ensuite découpés en petits segments, appelés chunks. Par défaut, chaque chunk fait 512 tokens (soit environ 300 à 400 mots), mais cette taille est paramétrable selon la finesse que vous recherchez.
Pourquoi découper ? Traiter un document entier n’est ni efficace ni pertinent. En travaillant sur des morceaux ciblés, l’IA peut identifier plus rapidement les parties utiles pour une réponse donnée.
3. Vectorisation du contenu
Chaque chunk est ensuite vectorisé, c’est-à-dire transformé en vecteur, une représentation mathématique du texte.
Pour vulgariser : imaginez qu’on transforme chaque paragraphe en coordonnées dans un espace à plusieurs centaines de dimensions. Plus deux vecteurs sont proches, plus les contenus se ressemblent.
Cette étape est cruciale : elle permettra ensuite à l’IA de retrouver les contenus les plus pertinents en fonction du sens, pas juste des mots-clés.
4. Indexation dans une base vectorielle
Les vecteurs sont stockés dans un index vectoriel, semblable à une base de données spécialisée pour l’IA. L’objectif : permettre une recherche ultra-rapide et intelligente lorsque l’agent posera une question.
Cette base devient le socle documentaire sur lequel l’IA s’appuiera, en temps réel, pour générer des réponses enrichies et contextualisées.
Utilisation au moment de l’inférence
5. Déclenchement du prompt avec RAG
C’est le moment où l’IA entre en action : on parle d’inférence, c’est-à-dire la phase où l’IA produit une réponse basée sur les données disponibles. Dans DataCloud et Agentforce, l’inférence est déclenchée par un prompt template, un modèle de question-réponse pré-paramétré par vos équipes. Ce prompt peut être lancé automatiquement par un agent virtuel ou intégré dans un processus métier.
Concrètement : un collaborateur pose une question dans Agentforce, ou un processus déclenche une demande à l’IA — le moteur RAG prend le relais.
6. Génération et vectorisation de la query
Pour que l’IA retrouve la bonne information, sa première étape est de transformer la question en vecteur, tout comme on l’a fait avec les documents. Cette vectorisation permet de comparer la requête à l’ensemble des contenus indexés, non pas mot à mot, mais en fonction du sens global.
Exemple : même si les termes exacts ne sont pas présents dans la documentation, l’IA peut comprendre que “procédure de remboursement” et “politique de retour” renvoient à des concepts similaires.
7. Recherche contextuelle par le retriever
Vient ensuite le rôle du retriever, littéralement le “chercheur”. Son objectif : parcourir la base vectorielle pour identifier les chunks les plus pertinents par rapport à la question posée.
Conclusion : Pourquoi cette approche change la donne
Grâce à ce mécanisme RAG (Retrieval-Augmented Generation), DataCloud et Agentforce vous permettent de créer des IA qui répondent avec précision, en s’appuyant sur vos propres documents internes.
Fini les hallucinations d’IA déconnectées de la réalité de l’entreprise. Avec la vectorisation, l’indexation et le retrieval, vos agents virtuels gagnent en fiabilité, en pertinence, et surtout en valeur ajoutée métier.
Résultat : la réponse finale n’est pas uniquement basée sur les connaissances générales du modèle, mais bien sur votre documentation métier spécifique, mise à jour et contextualisée.
")